

¿Cómo pueden los artistas visuales proteger su trabajo de los rastreadores de IA? Es complicado
La inteligencia artificial generativa se alimenta de datos que encuentra en la Red, pero cada vez más artistas quieren cerrarle la puerta. Un estudio revela por qué, aunque existen herramientas para frenar a los rastreadores de IA, la mayoría de creadores no puede —o no sabe— usarlas.
Por Enrique Coperías

Artistas visuales atrapados en el tiempo, luchando por proteger sus obras de los rastreadores de IA, reflejo de su falta de control técnico, según un estudio de la Universidad de California San Diego y la Universidad de Chicago para la Internet Measurement Conference 2025.
La inteligencia artificial generativa —la que da vida a herramientas como ChatGPT y DALL·E— se ha convertido en una fuerza creativa y disruptiva a partes iguales.
Pero detrás de sus respuestas fluidas y sus imágenes sorprendentes hay un secreto a voces: estas inteligencias artificiales (IA) se entrenan con cantidades masivas de datos extraídos de internet, muchas veces sin el consentimiento de sus creadores originales. Para conseguirlos, las empresas despliegan programas automatizados llamados AI crawlers o rastreadores de IA, que recorren páginas web para copiar textos, imágenes, audios y vídeos que alimentarán a los modelos.
Un equipo de investigadores de la Universidad de California en San Diego y de la Universidad de Chicago ha decidido poner cifras, contexto y matices a esta batalla digital. Su trabajo, que se presentará en octubre de 2025 en la Internet Measurement Conference de la ACM en Madison (Wisconsin) y que aparece publicado en el repositorio ArXiv, estudia cómo los creadores de contenido —especialmente los artistas visuales— pueden protegerse, qué herramientas existen, cuáles usan realmente y hasta qué punto son eficaces.
«En el núcleo de este conflicto está la idea de que los creadores ya no quieren controlar solo si su contenido es accesible, sino cómo se usa. Aunque esos derechos están claros en las leyes de copyright, no son fáciles de expresar, y mucho menos de hacer cumplir, en el internet actual», escriben los autores.
El triple frente de los rastreadores de IA
Los investigadores, con Enze Liu, de la UCSan Diego, al frente, distinguen tres grandes familias de rastreadores:
1️⃣ Rastreadores de entrenamiento de modelos: recogen datos para mejorar los grandes modelos lingüísticos o generativos, como hace, por ejemplo, GPTBot de OpenAI.
2️⃣ Rastreadores para asistentes de IA: buscan información puntual para responder consultas en tiempo real, caso de ChatGPT-User y Meta-ExternalAgent.
3️⃣ Rastreadores para buscadores con IA: indexan contenido para motores de búsqueda con componentes generativos.
En teoría, algunas empresas aseguran que el contenido recogido por los dos últimos no se usa para entrenar modelos de IA. En la práctica, los creadores no tienen forma de verificarlo ni de impedir usos no consentidos.
El arsenal de defensa: de la cortesía al bloqueo
La defensa más conocida contra estas prácticas es el archivo robots.txt, que se coloca en la raíz de una web para indicar qué bots pueden o no acceder a su contenido. Es un protocolo de cortesía: no hay obligación técnica de obedecerlo, y los rastreadores desobedientes pueden ignorarlo por completo.
Existen otras medidas:
✅ Metaetiquetas NoAI, que desaconsejan el uso del contenido para entrenar IA.
✅ ai.txt, propuesta por Spawning AI con un enfoque más explícito hacia los derechos de autor.
✅ Bloqueo activo de rastreadores, que identifica a los bots de IA y les impide acceder, devolviendo errores, captchas o incluso datos falsos. Cloudflare, por ejemplo, ha lanzado su función Block AI Bots.
Qué hacen las grandes webs
Tras analizando 40.000 sitios web populares durante los años 2022 y 2024, Jung y sus colegas detectaron un rápido aumento de robots.txt con prohibiciones específicas para bots de IA tras la aparición de GPTBot y ChatGPT-User.
Sin embargo, la tendencia se moderó e incluso retrocedió: algunas webs retiraron las prohibiciones al firmar acuerdos de licencia de datos con empresas de IA. The Atlantic, Vox Media y grupos como Condé Nast figuran entre ellos.
En paralelo, crece —aunque aún es minoritario— el grupo de webs que invita explícitamente a bots como GPTBot. Algunas son tiendas online que buscan visibilidad web; otras, páginas de desinformación que, según los autores, podrían querer infiltrar sus mensajes en modelos de lenguaje.
Los artistas, en desventaja técnica y contractual
En el estudio podemos leer que los más afectados no son los grandes portales, sino los creadores individuales. La encuesta a 203 artistas visuales profesionales deja claro que la preocupación es mayoritaria:
👩🎤 El 79% cree que la inteligencia artificial afectará moderada o gravemente a su seguridad laboral.
👩🎤 El 83% ha tomado medidas: el 67% usa Glaze (herramienta creada en Chicago que camufla las imágenes), el 60% publica menos obras y el 51% solo en baja resolución.
👩🎤 El 96% querría contar con un mecanismo para bloquear rastreadores de IA.
Pero aquí aparecen las barreras:
👨🎤 El 60% no conocía robots.txt.
👩🎤 Muchos no tienen acceso para modificarlo, porque su web está alojada en plataformas cerradas.
👩🎤 Entre quienes pueden, pocos lo usan por desconocimiento técnico.
👩🎤 La desconfianza es alta: creen que muchas empresas de IA no lo respetarán aunque esté configurado.
«Aunque se trata de una “nueva opción alentadora”, esperamos que los proveedores sean más transparentes con respecto al funcionamiento y la cobertura de sus herramientas; por ejemplo, proporcionando la lista de bots de IA que están bloqueados», afirma Elisa Luo, una de las autoras del artículo y estudiante de doctorado del grupo de investigación de Stefan Savage, del Departamento de Informática e Ingeniería de la UCSan Diego.
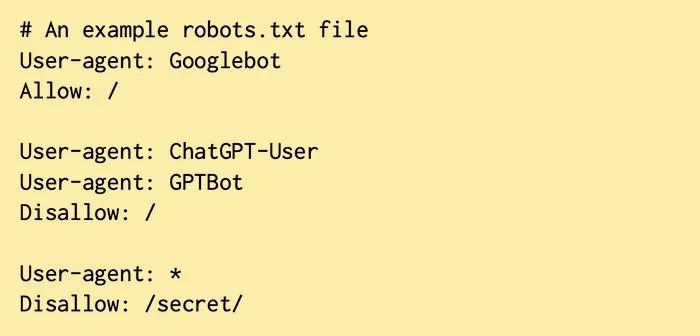
En este ejemplo de archivo robots.txt, se permite a Googlebot rastrear todas las URL del sitio web, se prohíbe a ChatGPT-User y GPTBot rastrear cualquier URL y se prohíbe a todos los demás rastreadores rastrear las URL del directorio /secret/. Cortesía: University of California en San Diego
El cuello de botella: las plataformas de alojamiento
El análisis de 1.182 webs de artistas muestra que más del 78% usa plataformas como Squarespace, ArtStation y Wix. La mayoría no permite modificar robots.txt.
✅ Squarespace ofrece un botón para bloquear IA, pero solo el 17% de los artistas lo ha activado.
✅ Wix (en su versión de pago) permite editar libremente, pero ninguno de los analizados lo había hecho.
✅ Otros proveedores o no ofrecen opciones o solo afectan a motores de búsqueda tradicionales.
En algunos casos, el problema es también de comunicación: Squarespace no explica que su botón funciona vía robots.txt y que no bloquea todo tipo de rastreo.
¿Respetan los bots las prohibiciones?
La respuesta, según los autores de este trabajo, es matizada:
✅ Grandes corporaciones: la mayoría respeta robots.txt (salvo Bytespider, de ByteDance/TikTok).
✅ Bots de asistentes de IA: muchos no lo consultan ni lo cumplen, sobre todo los de aplicaciones de terceros en entornos como ChatGPT.
✅ En el caso de Cloudflare, solo un 5,7% de los sitios que usan su función Block AI Bots la tienen activada, aunque los que lo hacen suelen mostrar también intención de protegerse en robots.txt.
Bloqueo activo: potencial y límites
En los 10.000 sitios más visitados, un 14% bloquea de forma activa a rastreadores de Anthropic, aunque rara vez combina esta medida con robots.txt.
El bloqueo activo no siempre es sustituible: si un bot sirve tanto para indexar como para entrenar IA (caso de Googlebot), bloquearlo implica perder visibilidad en buscadores. Aquí robots.txt permite un control más fino.
Pero también hay opacidad: servicios como Cloudflare no publican la lista completa de bots bloqueados, lo que dificulta a los usuarios entender su nivel de protección web.

La guerra silenciosa contra los rastreadores de IA. El 79% de los artistas visuales encuestados para el estudio cree que la inteligencia artificial afectará moderada o gravemente a su seguridad laboral y el 96% querría contar con un mecanismo para bloquear rastreadores de IA. Pero el 60% no conocía que existe robots.txt. para frenar la embestida de la IA. Imagen generada con Gemini
Dimensión legal y marco internacional
El estudio subraya que la batalla técnica se da en paralelo a una incertidumbre jurídica:
👩🏾⚖️ En Estados Unidos, los tribunales debaten si el entrenamiento con datos de internet está amparado por el uso justo (fair use).
👩🏾⚖️ En la Unión Europea, la nueva Ley de IA exige autorización expresa de los titulares de derechos para usar sus datos.
👩🏾⚖️ Si en Estados Unidos se consolida la defensa del fair use, podría reducir las vías legales y aumentar la presión para aplicar controles técnicos de acceso.
«La confusión sobre las posibilidades de recurso legal solo va a enfocar aún más la atención en los controles técnicos de acceso. Si se debilitan los remedios legales sobre el uso de datos, habrá una demanda aún mayor para reforzar el control sobre el acceso», explican los autores.
Un campo de batalla por definir
El trabajo pinta un panorama en el que la defensa contra los rastreadores de IA está marcada por:
✅ Una alta demanda de herramientas, pero escaso conocimiento y poca accesibilidad.
✅ Un ecosistema técnico en el que las medidas actuales son fragmentarias y dependen de la buena fe de los bots.
✅ Plataformas de alojamiento que a menudo actúan como cuello de botella para la implementación de defensas.
✅ Un marco legal que no termina de dar certezas.
En este escenario, la estrategia más efectiva parece ser una combinación de medidas: usar robots.txt, aplicar bloqueo activo cuando sea posible, y emplear herramientas como Glaze para proteger imágenes. Pero, como advierten los autores, ninguna de ellas es perfecta ni suficiente por sí sola.
Mientras tanto, la red sigue siendo un campo abierto: cada día, millones de peticiones automatizadas capturan fragmentos del trabajo creativo para alimentar a máquinas que, paradójicamente, pueden acabar compitiendo con sus propios creadores. ▪️
Información facilitada por la Universidad de California en San Diego
Fuente: Enze Liu et al. Somesite I Used To Crawl: Awareness, Agency and Efficacy in Protecting Content Creators From AI Crawlers. ArXiv (2025). DOI: https://doi.org/10.48550/arXiv.2411.15091